An enterprise data warehouse (EDW) is the beating heart of a healthcare organization’s analytic capabilities. Successful EDWs can provide hugely valuable insights. Unsuccessful EDWs become black holes of effort and morale.
Organizations have many decisions to make when building an EDW. What database technology should they use? On-premise or cloud? What levels of access should different constituencies have to sensitive data? What about disaster recovery?
Among the most consequential decisions are those related to what information the EDW contains, and how that information is organized: that is, the “data model” of tables, columns, and the relationships between them.
Over the years, Ursa Health has developed a playbook for building healthcare data models that are flexible, usable, and performant. One foundational design decision is to organize tables into a “hierarchical data model.” In this Master Class, we describe this approach in detail, and outline its benefits compared to traditional “flat” EDW data model designs.
What is a hierarchical data model?
Simply put, a hierarchical data model is a data model that builds on itself.
Tables in a hierarchical data model are populated using queries that can draw from other tables that are themselves full-fledged members of the data model. This is roughly analogous to object-oriented approaches in traditional application software development, with tables playing the role of objects: modular components that can be reused and combined to create new objects. The “hierarchy” is created by the relationships between antecedent “upstream” tables and descendent “downstream” tables.
In contrast, the traditional data model is flat, with each EDW table effectively the final destination of its data within the EDW. Of course, data from these tables will be transformed by downstream processing—for example, ad hoc queries, stored procedures producing data marts for a particular business unit, business intelligence tools—but this activity is not considered to be part of the EDW, and the resulting data analytic work product is never returned to the EDW for others to use.
This might seem like a trivial distinction, or perhaps just an issue of semantics—why not consider those downstream data assets “in the EDW” as well? In practice, however, the implications are profound. To help explain why, we’ll set up a concrete example.
Let’s say we are working with healthcare claims data, so our EDW includes tables for professional claims, institutional claims, pharmacy claims, plan membership periods, patients, providers, and more. The desired analytic deliverable is a list of patients with at least one office visit with a primary care provider (PCP) in the last six months.
Working from an EDW with a traditional, non-hierarchical data model, a developer might write a SQL script to draw records out of the EDW’s claims tables and produce the final deliverable. Along the way, some temporary tables might be created, but those would be dropped upon completion of the procedure.
 Figure 1. Traditional data model
Figure 1. Traditional data model
In a hierarchical data model, instead of generating the desired output in a single step, a series of incremental transformations are executed, generating three additional intermediate tables along the way, which will themselves become part of the EDW’s data model.
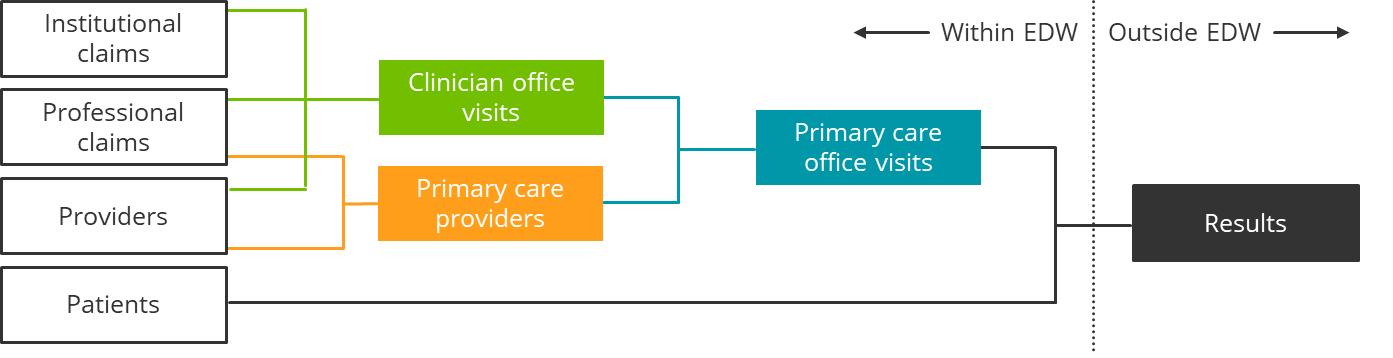 Figure 2. Hierarchical data model
Figure 2. Hierarchical data model
This process might take a bit more time and care compared to the traditional approach—after all, there are effectively four new deliverables here, rather than just one—but the future payoff is substantial, as we’ll see below.
Heightened reusability
Probably the most important benefit of this approach is that future development efforts can more effectively reuse the work from earlier projects. Consider the future data analytic tasks that might benefit from the three intermediate objects added in our example. For example, the Clinician Office Visit object, originally created as a stop along the way to primary care office visits, would likely be very useful as a starting point to identify specialist office visits as well. Notably, in addition to savings in development person-hours and calendar days, teams will benefit from the standardization and reliability that come with using a shared set of battle-tested assets.
It’s worth spending a moment to explore what exactly prevents this from happening in a traditional data modeling approach. The most obvious reason is that the traditional approach simply never creates those intermediate tables in any persistent form. The best option available to subsequent projects, therefore, will be to excavate the part of the logic that identifies, say, office visits, and graft that piece of SQL into the new script. This scenario assumes the new team is aware of that existing logic and knows where to find it—assumptions that are often violated in practice, especially in larger organizations.
However, this logic will most likely be difficult to reuse simply because those initial development efforts were under no obligation to generate something reusable. Maybe the original logic included a restriction to a particular geographic region or patient population that was relevant for the original deliverable but would not generally be needed in other contexts. Future attempts to repurpose the original code might have trouble accurately disentangling these non-essential snippets of logic from the essential.
In brief, we have found that unless data assets are designed to be reused, they will not be.
A hierarchical data model gives teams the flexibility they need to extend their EDW in an orderly way as unanticipated data analytic needs arise, as they always do. In traditional EDWs, these new concepts might, at most, be jammed into existing tables as columns (for example, adding “Is PCP Office Visit Claim” flags in the Professional Claims and Institutional Claims tables). A hierarchical data model, in contrast, has space for the cleaner solution of creating dedicated new tables. We have found that this approach—in other words, planning for and facilitating the extension of a data model over time, what we call a “Living Data Model”—to be an essential part of an effective data analytic infrastructure.
Greater accuracy and consistency
Another category of benefit relates to definitional accuracy and consistency. Hierarchical data models, insofar as they tend to push complicated or potentially disputed logic out of the shadows of deliverable-specific scripts and into the bright spotlight of a centralized EDW, encourage good data governance and consistent enterprise definitions.
In our example, consider that the act of creating a new EDW table of primary care providers would, if done properly, involve reaching consensus on what the organization’s definition of a primary care provider is. Should it include only physicians, or are nurse practitioners and other staff included as well? Which physician specialties should be considered primary care providers rather than specialists? Which constituencies in the organization should weigh in on this definition?
If one were creating only a single deliverable, there might not be the same pressure to reach a durable organizational agreement on these definitional questions. However, making that initial investment of time and effort is nearly always going to be worthwhile, benefiting both current and future development efforts.
These definitions can become complicated. Because hierarchical data models encourage the creation of intermediate tables, however, it is relatively easy to step back through the individual components of a potentially complex chain of logic to understand what is happening to the data, and to review and debug each concept in isolation. (In the traditional approach, the three intermediate concepts in our example might exist only as transient subqueries in the middle of a long script.)
But perhaps the greatest advantage of a hierarchical data model with respect to accuracy (i.e., ensuring the code faithfully implements the desired rules) is that these tricky sequences of logic need only be implemented once. Organization can assign the developers most likely to get it right, and the time it takes for thorough review and testing becomes more practical.
Improved performance
Finally, hierarchical data models tend to promote good database performance, especially as the EDW grows.
First, this approach shifts potentially duplicative processing in downstream siloes back upstream into the actual EDW, where they are executed only once per batch run. For example, characterizing a provider as a PCP might involve a fair amount of database computation: looking up providers’ specialties, synthesizing their history of rendered services and referrals, interpretation of unstructured data in clinical notes or other documentation, and more. Better to do all that processing once, in the EDW, rather than potentially multiple times in all the downstream deliverables that require the concept of a PCP. In addition, that additional logic will likely be run during off-hours as part of the routine EDW refresh, which is less likely to be the case for downstream systems.
Second, simply breaking a complex sequence of logic into multiple steps will often produce better performance because users will be able to apply the full set of DBMS optimization tools—for example, indexes and partitions—at each stop along the way. With this approach, the optimizer will have more opportunity to understand the contents of each intermediate table (via gathering statistics), leading to smarter query plans.
Costs of adopting a hierarchical data model
Nothing comes for free, and teams should anticipate some additional costs—mainly in the short run—to realize the benefits of a hierarchical data model.
The first cost is the additional up-front development effort it takes to build something to be reusable. Certain simplifying assumptions that would otherwise offer a shortcut might not be possible; additional fields might be needed that wouldn’t otherwise be; and high-quality documentation of the code and the contents of tables (consistent with the usual standard applied elsewhere in the EDW) becomes a necessity.
Second, because the responsibility for deciding where and when to create those reusable intermediate tables falls to developers, a hierarchical data model approach requires developers to have a good understanding of the subject matter. For example, one would have to know something about how healthcare is delivered to anticipate that it would be useful to branch off the logic for clinician office visits from the logic for identifying primary care clinician office visits. (The key knowledge in this case being that a table of clinician office visits for non-primary care providers is very likely to be needed for other data analytic tasks.) Developers with both good technical chops and good healthcare subject matter knowledge are not always easy to find, although organizations are probably already looking hard for these kinds of candidates.
Third, and perhaps the most daunting practical challenge for most teams, is the need to keep track of the network of dependencies between upstream and downstream EDW tables so that refreshes can be executed in the correct sequence. For example, in our example, the Clinician Office Visit object can only be refreshed after both the Professional Claims and Institutional Claim objects have been successfully refreshed. Without some degree of automation, this task quickly becomes very work-intensive with even modestly sized data models. (Given the centrality of the hierarchical data model to our approach, arguably the most indispensable feature of our healthcare analytics development platform, Ursa Studio, is its ability to automatically track object dependencies and execute full and partial data model ELTs in the most efficient sequence.)
Finally, EDWs with a hierarchical data model, assuming they follow the Living Data Model approach, tend to grow quite quickly, and so certain maintenance tasks becomes a greater burden. In particular, because each table might be referenced by many (rather than one) downstream constituencies, changes to column names or to the grain size of a table must be performed with great care, and with the expectation that a significant amount of downstream logic might need to be updated.
However, it’s also worth noting that other maintenance tasks become much simpler when logic is consolidated in a single location, as in a hierarchical data model. Enhancements to business logic, bug fixes, or query optimization often need only be applied once, to a single table, and all analytic deliverables referencing that table immediately benefit. Using our example, imagine that a new, better method of identifying primary care providers was developed; once the Primary Care Providers table was updated to use that new logic, all downstream objects would immediately incorporate it. In contrast, with that logic scattered across some (probably unknown) number of ad hoc scripts and stored procedures in the traditional model, it might take days just to locate all instances of the old logic, let alone implement it across all those different contexts.
A superior approach
Hierarchical data models represent a more modern approach to EDW design that we believe is superior to traditional, flat EDW structures; the evolution from procedural to object-oriented programming offers a useful analogy. Although the initial investment of effort is non-trivial, our experience has been that, with the appropriate tooling, team composition, and data governance practices, hierarchical data models provide a huge benefit, greatly reducing time and effort for new development while enforcing definitional consistency and accuracy across an organization’s analytics.