Overview
Source data is brought into Ursa Studio without modification. The first step in transforming the source data into usable downstream data is semantic mapping, which can be as simple as conforming the source data columns to a standard set of column names, or mapping text fields to date or number fields. More sophisticated transformations are also possible. Indeed, semantic mapping allows users to access the full breadth of derived field patterns. Semantic mapping objects can be built off of any objects which allow themselves to be visible to the semantic mapping layer: typically, import objects and registered table objects.
To create a semantic mapping object users should navigate to the Object Workshop home screen and click the plus sign icon in the upper right corner. In the Create New Object screen, select the Semantic Mapping tile. In the Semantic Mapping object screen, update the parameters listed in the panels detailed below. When the semantic mapping object's parameters have been specified, select the lightning bolt icon in the upper right corner of the screen. The browser then redirects back to the Object Workshop home screen where the object will be running in the ELT Progress blade.
Naming
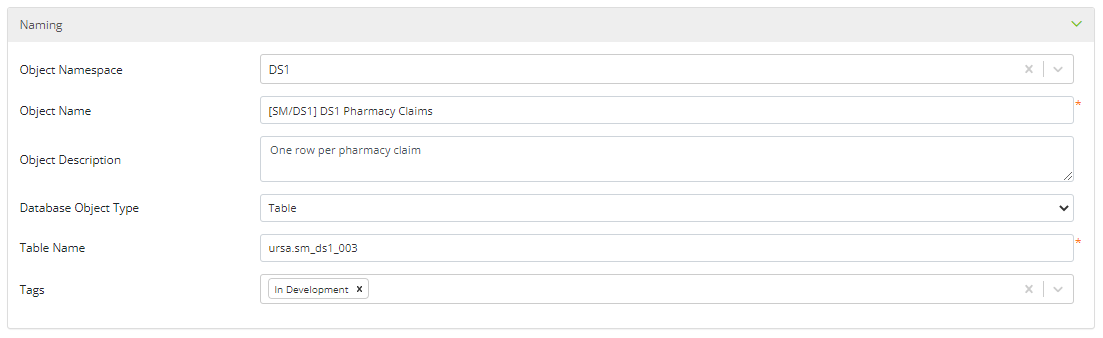
Object Namespace: Namespaces contain different information about data assets depending on the asset type, and in the case of objects, the associated data model layer. A semantic mapping object's namespace typically describes the data’s source, e.g., BCBS, Humana; etc.
Object Name: The object name is how the object will be referenced throughout Ursa Studio. The convention used by the Ursa Health team for naming semantic mapping objects has four parts, [“Source”]+[Namespace]+[File/Table Description]+["Semantic Mapping"]. In practice, the name of a semantic mapping object is the name of the import or registered table object being semantically mapped with "Semantic Mapping" appended. For example, if the name of the import object being semantically mapped is “Source ACMEHEALTH-BCBS Membership” then “Source ACMEHEALTH-BCBS Membership Semantic Mapping” would be the name of the semantic mapping object.
Object Description: The object's description provides a brief explanation on the contents of the object. The convention used by the Ursa Health team is to describe the grainsize of the table being mapped, e.g., “One row per member.” However, it is common for object descriptions to contain more than this minimum information.
Database Object Type: Semantic mapping objects can be created as tables or views. This option allows for that specification.
Table (or View) Name: This field captures the name of the table or view that will be created when the semantic mapping object is run. The Ursa Health team uses a convention for table or view names similar to the one used for object names. Semantic mapping object names follow the format, [“sm”]+[namespace]+[file/table description]. First, the token “sm” is used to indicate the object is associated with the Semantic Mapping layer of the data model. Second, the object’s namespace is included. Third, a brief description of the import file or registered table is included. For example, “sm_acmehealth_bcbs_membership” follows the convention for semantic mapping objects.
Tags: Tags are general purpose labels that can be applied to a variety of data assets in Ursa Studio for identification and categorization. For example, the Ursa Health team uses an "In Development" tag to identify objects and measures that are currently under development.
Configuration
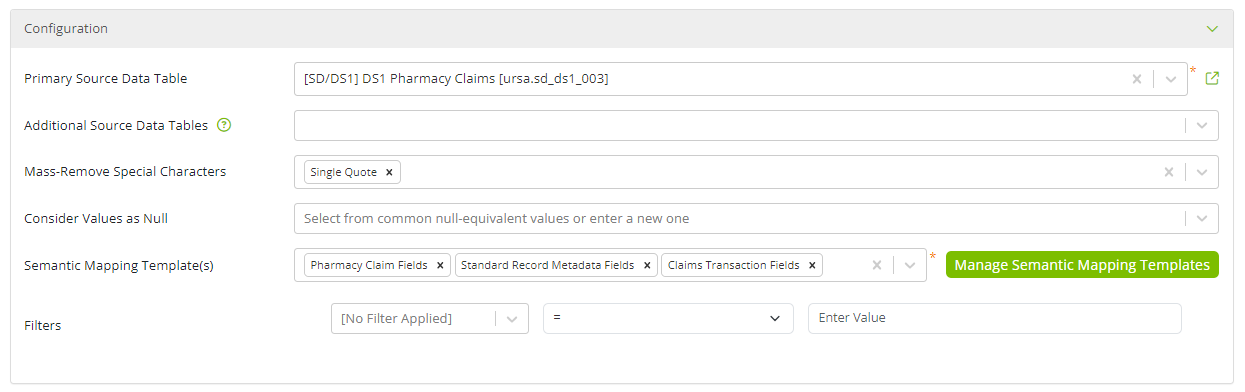
Primary Source Data Table: This field is for specifying which source data table is to be semantically mapped.
Additional Source Data Tables: More than source data table can be included in the mapping process when they share the same fields as the primary source data table.
Mass-Remove Special Characters: This option instructs Ursa Studio to strip out all of a particular symbol: comma, dollar sign, hyphen, single-quote, double-quote, or period. Even without one of these selected, preceding and trailing whitespace will always be trimmed. These transformations apply to every field in the source data table.
Consider Values as Null: Similar to Mass-Remove Special Characters, this option causes a given set of field values such as strings like "NULL", "NA", or "UNK" to be replaced with true NULL values. The field values to be replaced with NULL can be selected from the list of choices or manually entered into the field. When semantically mapping registered table objects, numeric or date column types will be matched if the selected fields are a number, or a date in the form YYYY-MM-DD, respectively.
Note that the mass-removal operation happens before the conversion to NULL, so that “ ‘NA’ “ would be converted to NULL if single quotes were mass-removed and if NA was considered NULL. As with mass removal of special characters, these transformations apply to every field in the source data table.
Semantic Mapping Template(s): This option enables users to select the semantic mapping template(s) needed to map the source data table's columns to Ursa Studio's standard column names. To create a semantic mapping object, users must first set up one or more semantic mapping templates.
The order of the columns in the finished semantic mapping table will be ordered first by field group, then by the ordering of the templates, then by the order of the field within each template.
The field group can be overridden in semantic mapping on a field-by-field basis. The resultant table column order will honor the field groups per the templates and overrides. The field group assigned to a semantic mapping field will automatically and immediately be flowed as the default through all descendant objects, but the column order of the semantic mapping table will only be updated upon re-ELT.
Filters: This option allows users to work with a partition of the upstream source data table. Users can filter based on value sets by invoking the IS IN VALUE SET and IS NOT IN VALUE SET operators. With each filter, users can choose any field from the source data table. The filtering will be performed on the raw, untrimmed values of the source data.
Intermediate Derived Fields
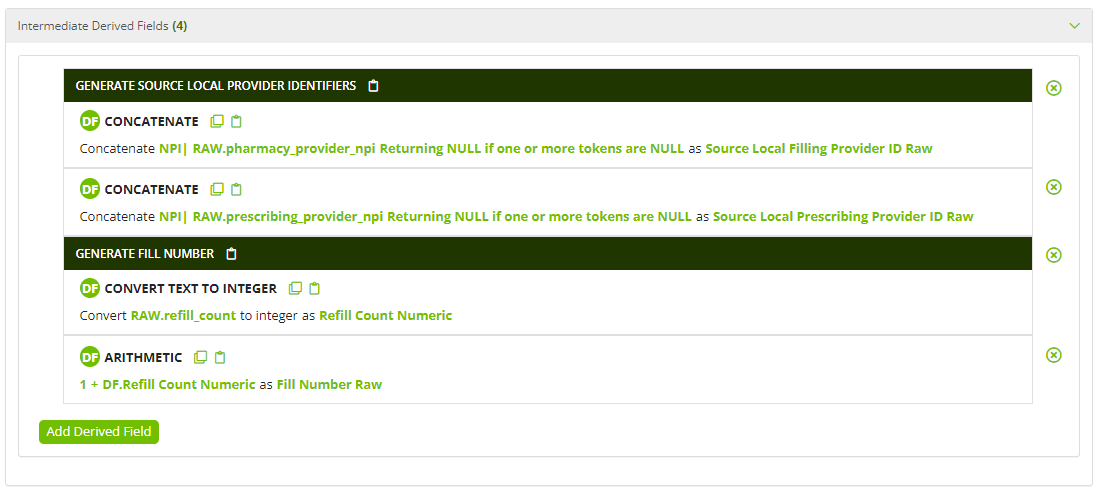
The Intermediate Derived Fields panel presents users with the opportunity transform data from the source data table prior to completing the field mapping exercise in the Template Fields panel. This opportunity is particularly useful when an field on the source data table requires multiple derived field patterns to complete a single transformation.
As an example, imagine a user is semantically mapping a source data table containing pharmacy claims data. The source table has a "Refill Number" field that needs to be mapped to the "Fill Number" field from the semantic mapping template. The "Refill Number" field is zero-indexed, i.e., the first fills have a value of zero because they are not refills. The "Fill Number" field is expecting a one-indexed value because it reports whether the fill is the first, second, third; etc. fill in the prescription. This mapping would require the "Refill Number" data to be transformed to the expectations of the "Fill Number" field. This transformation would require two derived field patterns - Convert Text to Integer and Arithmetic. The Convert Text to Integer pattern casts the "Refill Number" data to an integer, and the Arithmetic pattern is used to add the number one to each value in the "Refill Number" field. The user can now map the derived field created with the Arithmetic pattern to the "Fill Number" field.
Template Fields
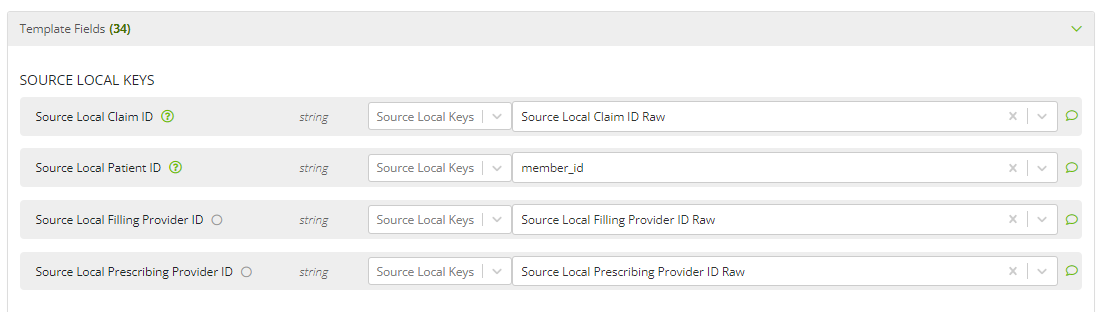
The main objective in semantic mapping is to work through the expected output fields, as defined by the assigned templates, and determine how to massage the source data to arrive at the desired output. It is often helpful to see sample contents and the summarized information for the source data table itself, which can be found by clicking the debug link at the top of the page.
In the simplest case, a user selects a source data field that matches the desired output field. The source data field will automatically be trimmed of whitespace, converted as necessary into the output data type, and renamed per the template. If the output type is a date field, then the user should enter a date format for the conversion (e.g., YYYY-MM-DD). Ursa Studio will automatically detect mask format for text-to-date conversion among a range of common masks if no mask is supplied.
The range of allowable date formats depends on the type of database; the date format the user enters is passed as an argument into the database’s native convert function. For Microsoft databases (MSSQL and Synapse Analytics), the supported date formats can be found in the T-SQL documentation for the CONVERT function. For the MSSQL-family date formats, the Ursa Studio match to the available date format is not case-sensitive, but it does not correct duplicate characters (e.g., between M/D/YYYY and MM/DD/YYYY).
It is also possible to draw on the import metadata that was entered at the moment of data import, such as the effective dates or the source filename. The “source” import metadata captures the current source of the import object, not the source of the import object at the moment of import.
For more sophisticated transformations, users can select from the full range of derived field patterns, such as coalesce and concatenate. If needed, users can chain derived fields using the “Intermediate Derived Fields” panel—for example, if it is necessary to first coalesce and then concatenate some source data fields to the output.
If a source data table has fields with incremental numbering (e.g., dx_1_code, dx_2_code, dx_3_code) users will see an option to “Apply Array” across all of the fields that follow that pattern. The decision to apply the array will be saved with the object and will instruct Query Builder to have the subsequent fields follow the same pattern as the first item in the array.
Published Fields

The Published Fields panel, as with other objects, enables users to preview the object's column order and allows for manual re-ordering, either among field groups or within field groups.
Object Metadata
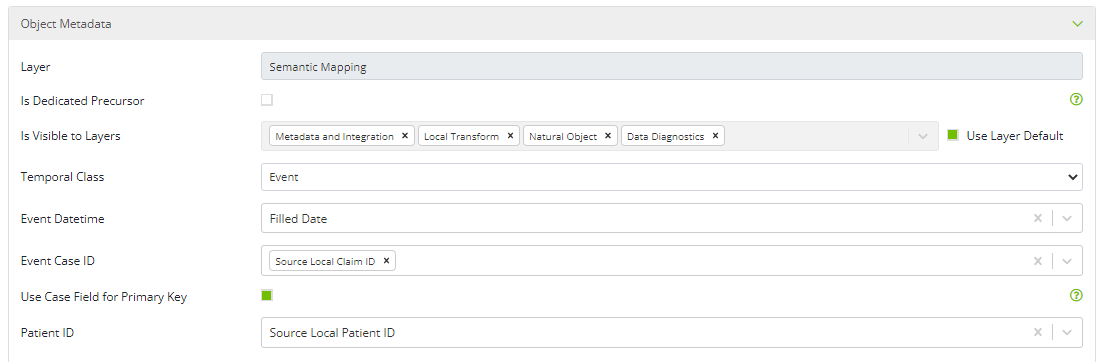
Layer: This field captures the data model layer the object is associated with. For semantic mapping objects this will always be the “Semantic Mapping” layer.
Is Dedicated Precursor: This option allows the object to be set as a dedicated precursor to a terminal object. It is atypical to select this option for a semantic mapping object.
Is Visible to Layers / Use Layer Default: This option specifies the object's visibility in the data model, i.e., which layers in the data model the object will be visible to. Semantic mapping objects can be made visible to Object Workshop and Measure Workshop. Unless there is a specific reason for altering the default visibility, which is uncommon, users should leave the default layers selected.
Temporal Class: Select the appropriate, temporal class for the object. Temporal class is a categorical description of an object’s relationship to time. Object can have a temporal class of event, interval, or entity. If a table’s records represent a moment in time, e.g., claims or ED visits, then select event. If a table’s records represent a period of time with a start and end date, e.g., episodes, then select interval. If a table’s records do not represent a moment in time or a period of time, e.g., a list of health plans or providers, then select entity.
Case ID: Select the field or fields that uniquely identify each record in the table.
Use Case Field for Primary Key: Select this option to use the field or fields selected in the previous option for the object's primary key.
Patient ID: If the table contains a field that identifies patients or members, select that field here.
Terms
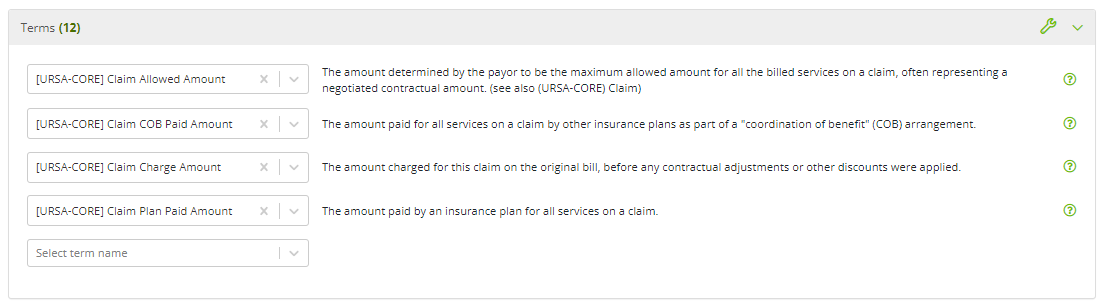
Users have the option of associating terms with the object by selecting terms from the dropdown in this panel. It is not uncommon for developers to see terms listed in this panel before they have manually added any. In the context of semantic mapping, terms can be associated with fields on semantic mapping templates. When a field with an associated term is mapped in the Template Fields panel, the field's term is automatically added in this panel.
Validation
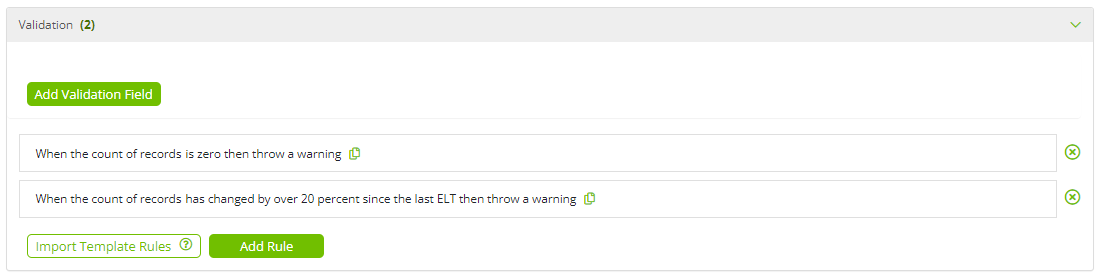
Add Validation Field: This option enables the addition of a derived field to be used as an input into a validation rule.
Import Template Rules: This option enables the import of derived fields existing on the semantic mapping template.
Add Rule: This option enables the addition of bespoke validation rules.
Object Backup

Store Backup on Next ELT: This option specifies that Ursa Studio should maintain a backup of the current table following the next ELT of the object.
Backup Table Name: This field displays the default name of the backup table that will be created. The default name can be overwritten as desired.
Current Backup: When an object has an existing backup table, the date and time of the most recent back up are displayed along with links to view the back up table in data review or delete the backup table.
Access and Use Restrictions

Prevent Passive ELT: This option ensures the object is never passively included in an ELT.
Lock Object: This option ensures the object is locked for editing until it is unlocked.
Incremental Load

Support Incremental Load: This option enables downstream objects to incrementally pull data from this object.
Tracking Field: When the previous parameter is selected, a date field used to determine which rows are more recent than the latest downstream ELT needs to be specified. This being the case, users should choose a field with values that never move backwards in time when new data arrive. When this option is left blank Ursa Studio automatically creates and manages a tracking field.
Execute Incremental Load: This option enables incremental loading of data into the object if possible.
Skip Deduplication Step: When users are confident the incremental data will not contain updates to the existing records, this option can be selected to skip the step in which existing primary keys are removed if they are contained in the incremental update. The ELT will be faster as a result of this selection. If this option is selected and the data does contain updates to the existing records, an error with a primary key violation will be presented during ELT.
ELT History

This panel captures the following ELT-specific metadata each time the object is run:
- ELT Date
- Elapsed Time
- Row Count
- Error Count
Revision History
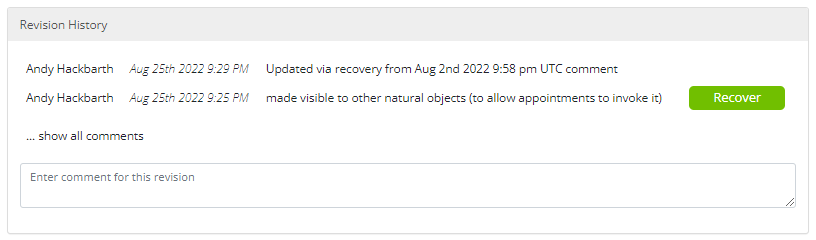
As its name suggests, this panel contains a timestamped change log that keeps track of all revisions to the object. Users can revert back to a previous version of the object by selecting the "Recover" button to the right of the timestamp and comment. When selected, users are prompted with two options. First, the recovered version of the object can be created as a new object, which will leave the current version unchanged. Second, the recovered version of the object can replace the existing version of the object. When this option is selected, the existing version of the object will receive a record in the change log and can be recovered in the future if desired.